You can find a summary of the code updates in this pull request . Read on for explanations.
1. Chat Completion Configuration
Let’s start by updating some Chat Completion configurations.
JSON mode
JSON mode ensures a JSON response, which is easier to parse (and tends to be less wordy, too!)
route.ts
const completion = await openai.chat.completions.create({
messages: [
{
role: "user",
content: "Describe Dolly Parton in three words"
},
],
model: "gpt-3.5-turbo",
response_format: { type: "json_object" },
});Temperature
Temperature determines how random the output is (the value is a number between 0 and 2, with 0 being more deterministic and stable, and 2 being the most randomized). The default value is 1; let’s use 0.7 to make it just a little less random:
route.ts
const completion = await openai.chat.completions.create({
messages: [
{
role: "user",
content: "Describe Dolly Parton in three words"
},
],
model: "gpt-3.5-turbo",
response_format: { type: "json_object" },
temperature: 0.7,
});Max Tokens
Just in case our prompt inadvertently causes ChatGPT to talk at length, let’s limit the output. The max_tokens option will cut off the response after a prescribed number of tokens .
route.ts
const completion = await openai.chat.completions.create({
messages: [
{
role: "user",
content: "Describe Dolly Parton in three words"
},
],
model: "gpt-3.5-turbo",
response_format: { type: "json_object" },
temperature: 0.7,
max_tokens: 256,
});2. Messages
Last workshop, we sent only one message (as a user). For the color prompt, let’s send two messages :
- a
systemmessage with instructions that would apply to any quote - a
usermessage that supplies the quote
System message
It took me a bunch of experimentation to come up with this message in src/app/api/get-quote-styles/route.ts, but it works well for my purposes. If you came up with a message you like better, I’d love to hear about it in a Substack comment, or in a LinkedIn or Twitter post.
Here’s my system message:
route.ts
const systemPrompt = `You will be provided with
a quotation, and your task is to generate:
1) a hex color code that matches the mood of the
quotation
2) a contrasting color to the hex color code that
matches the mood. The contrasting color should be
"black" or "white", whichever has the higher WCAG
contrast ratio compared to the color that matches
the mood.
Write your output in json with these keys:
"hex_color"
"text_color"
`;
export async function GET() {
const generatedQuote = getRandomQuote();
const messages = [
{
role: "system",
content: systemPrompt,
},
];
const completion =
await openai.chat.completions.create({
messages,
model: "gpt-3.5-turbo",
response_format: { type: "json_object" },
temperature: 0.7,
max_tokens: 256,
});
// ...
}You may have noticed a cryptic TypeScript error when tried to add this message to the chat completion options, something like this:
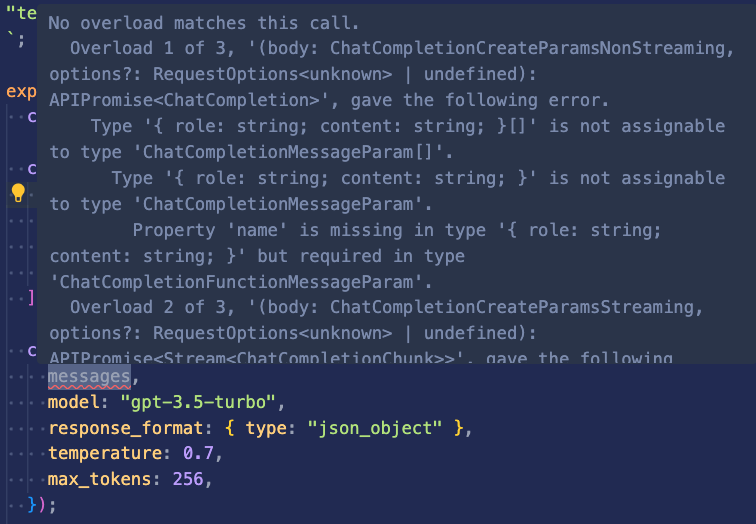
To avoid this error, we need to specify as const for the "system" value:
route.ts
const messages = [
{
role: "system" as const,
content: systemPrompt,
},
];You can read more about this requirement in this GitHub issue and the TypeScript docs on literal inference .
User message
The user message supplies the quote that we promised in the system message. To satisfy TypeSript, we need to use as const for the "user" value as well.
route.ts
export async function GET() {
const generatedQuote = getRandomQuote();
const messages = [
{s
role: "system" as const,
content: systemPrompt,
},
{
role: "user" as const,
content: generatedQuote,
},
];
// ...
}3. JSON response
Let’s parse the chat completion and send the data back to the user according to the spec.
Parsing the completion
We might start with something like:
route.ts
const styles = JSON.parse(
completion.choices[0].message.content
);Unfortunately, this triggers a TypeScript error:
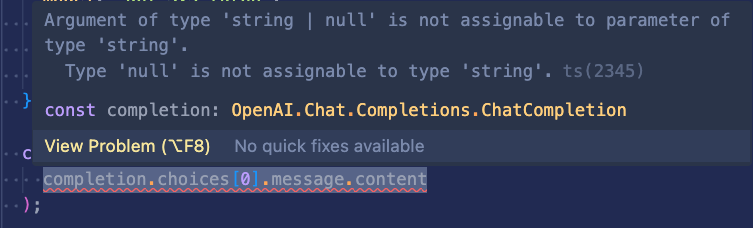
TypeScript is upset that completion.choices[0].message.content could be null, and JSON.parse can’t take a null argument. We’ll can to account for that with an early return:
route.ts
const rawStyles =
completion.choices[0].message.content;
if (!rawStyles) {
return NextResponse.json({
quote: generatedQuote
});
}
const styles = JSON.parse(rawStyles);Returning JSON
Now we can return the JSON according to the spec:
route.ts
const styles = JSON.parse(rawStyles);
return NextResponse.json({
quote: generatedQuote,
colors: {
background: styles.hex_color,
text: styles.text_color
},
});try/catch
Finally, let’s wrap the JSON.parse in a try/catch block, just in case the completion returns invalid JSON (if rawStyles is not valid JSON, then JSON.parse() will throw an error).
route.ts
try {
const styles = JSON.parse(rawStyles);
return NextResponse.json({
quote: generatedQuote,
colors: {
background: styles.hex_color,
text: styles.text_color
}
});
} catch (error) {
// in production app, we'd record
// the error to log files, but here
// we'll log the error to the console
console.error(error);
return NextResponse.error();
}4. View the result
You can access http://localhost:3000/api/get-quote-styles to see the JSON response. You’ll get something like this:

(Any grammatical errors in the quotes will be corrected by OpenAI in a future workshop! 😊)
Up next
In the next workshop , we’ll apply these colors to the quote in the UI.
Workshops in this series
- OpenAI Node SDK
- Prompt engineering: color
- Apply color response
- Prompt engineering: quote cleanup and font
- Apply font response
- Quote entry