You can find a summary of the code updates in this pull request .
Step 1: Account for MDX italics
Remember the italicized heading word we added in Workshop 2? In the last workshop, we handled those italics when creating an id within BlogHeading. There, we passed children to headingToId . For the heading with the italicized heading word, children looks like this:
Understanding Your Learning <em>Style</em>The em tags are handled by reactToText .
That’s great for JSX. However, in this workshop we’re going to be using the MDX to create the id. In Markdown, underscores (_), can be used for italics . headingToId does a pretty good job of removing special characters, but it lets all of the characters of \w character class remain. And the /w character class includes all alphanumeric characters and the underscore character.
So, first item of business: add a line to headingToId to remove underscores, so that both JSX headings and MDX headings get the italics notation removed.
headings-helpers.ts
export const headingToId = (
heading: string | React.ReactNode
) => {
const headingText = reactToText(heading);
return (
headingText
.toLowerCase()
.replace(/[^\w\s-]/g, "")
.replace(/_/g, "")
.replace(/\s+/g, "-")
);
};Step 2: Update extractMdxHeadings to return id
Now that we have a headingToId function that can handle MDX input, let’s call it in extractMdxHeadings. First, we’ll add id to the HeadingData interface:
headings-helpers.ts
export interface HeadingData {
title: string;
level: number;
id: string;
}Then we can call headingToId in extractMdxHeadings and add the id to the heading objects:
headings-helpers.ts
export function extractMdxHeadings(
mdxContent: string
): Array<HeadingData> {
const headings: Array<HeadingData> = [];
// match the `#` syntax for headings
const headingMatcher = /^(#+)\s(.+)$/gm;
let match = headingMatcher.exec(mdxContent);
while (match !== null) {
const level = match[1].length;
const title = match[2].trim();
if (level === 2 || level === 3) {
// get the id for the heading
const id = headingToId(title);
// record this heading
headings.push({ title, level, id });
}
// get next match
match = headingMatcher.exec(mdxContent);
}
return headings;
}Step 3: Add links to table of contents
Here’s what ToC.tsx looks like after we’ve added the headings links:
ToC.tsx
function ToC({ headings }: ToCProps) {
return (
/* ... */
{headings.map(({ id, title, level }) => {
return (
<a
// this key assumes no duplicate heading titles
key={id}
href={`#${id}`}
className={styles[`heading${level}`]}
>
<MDXRemote source={title} />
</a>
);
})}
/* ... */
);
}Let’s break that down:
- line 4: destructure the
idwhen mapping over theextractMexHeadingsreturn value - lines 6 and 13: Change the
spantoa, to turn the element into a link - line 8: Use the
idas the key instead of thetitle. (There’s no real functional benefit here; I just find it tidier knowing the id has been cleaned up a bit from the title. Either way, the headings need to be unique in the blog post for the key to be unique .) - line 9: Use the
idwith a#in front of it as thehref, to link to the element with thatidon the page . This also relies on the headings being unique on the page; otherwise the link will always go to the first heading with thatidon the page.
We’re getting pretty close! Our biggest problem is that the link brings the heading with the corresponding id to the top of the page, burying it under the header:
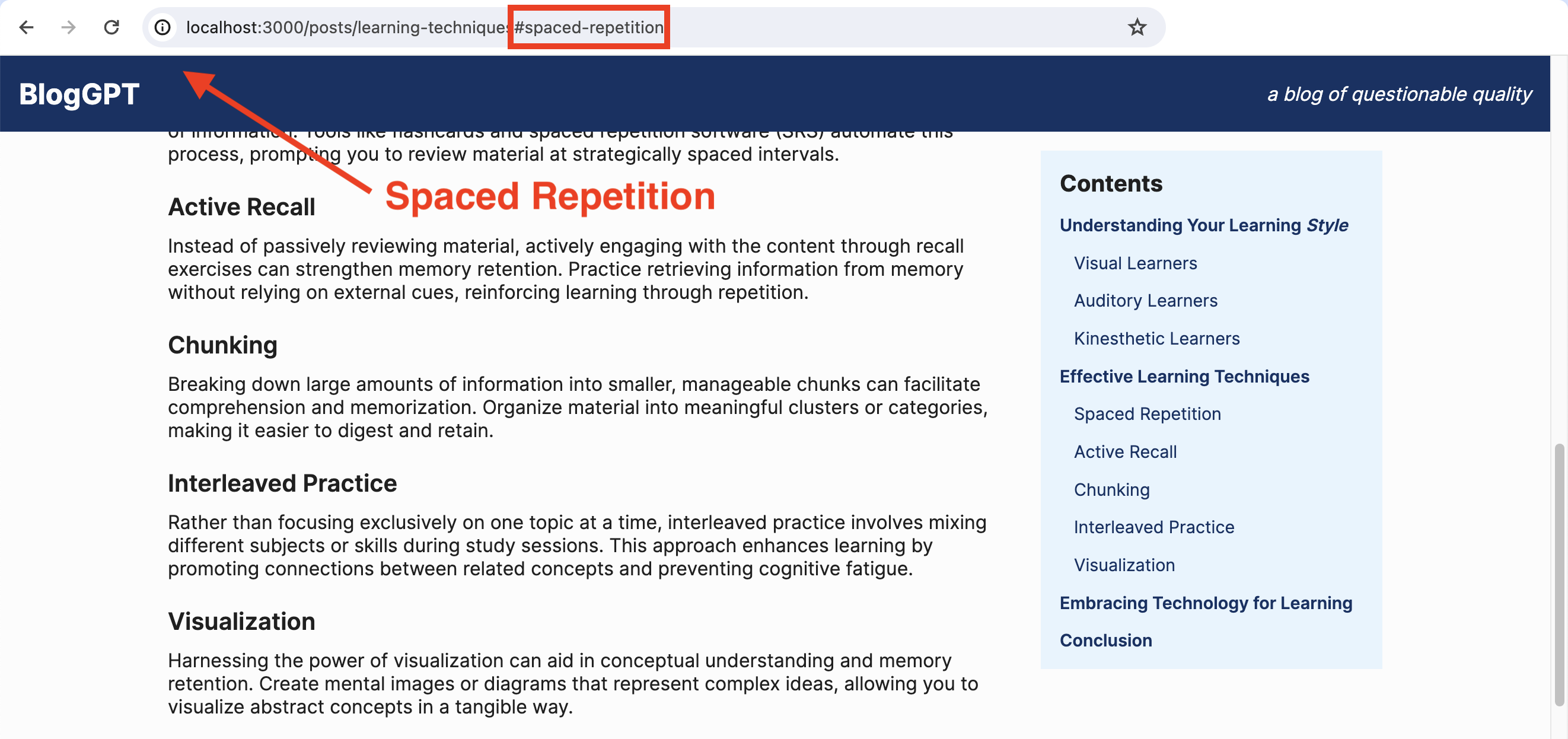
We’ll fix that (and add smooth scrolling to the header position) in the next, and final, workshop of this series.
Workshops in this series
- Extract the headings from the MDX
- Create a table of contents from the headings
- Make the table of contents sticky and responsive
- Add a descriptive id for each heading
- Link each item in the table of contents to the heading location in the blog post
- Scroll smoothly and adjust position for header